Semantische Ähnlichkeit für Bilingwis. Ein Vektorraummodell-Ansatz
Autor: Gianluca Macauda
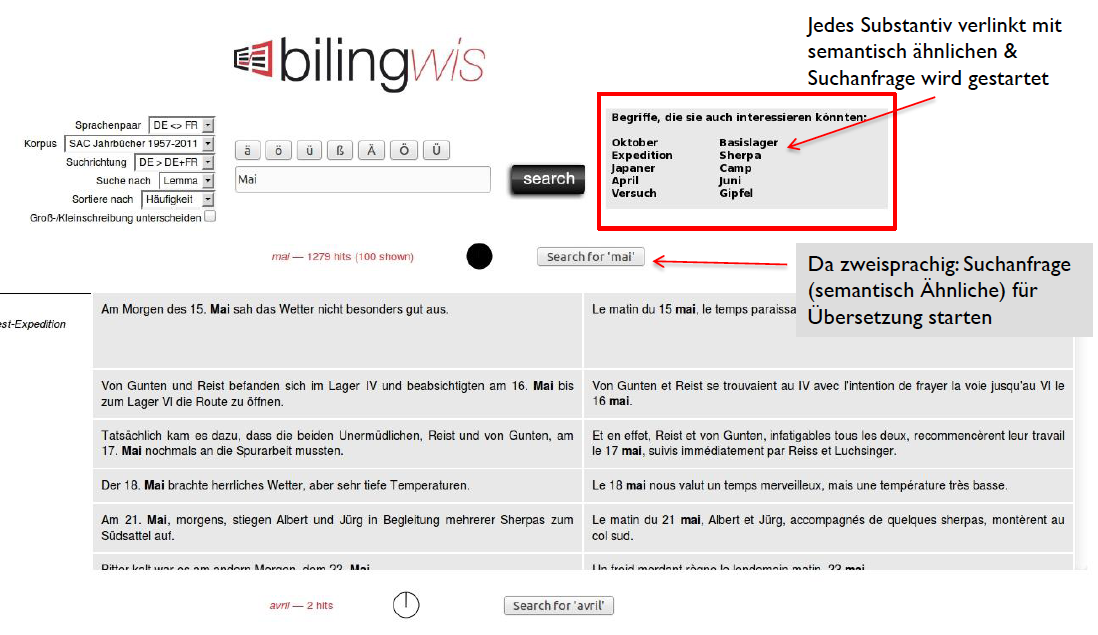
Basierend auf dem Text+Berg-Korpus wurde ein System erstellt, dass die zehn semantisch ähnlichsten Wörter zu den 1'000 häufigsten Lemmata des Text+Berg-Korpus ausgibt und zwar für Deutsch und Französisch. Das Besondere daran ist, dass das System ohne jegliches semantisches oder sonstiges sprachliches Wissen läuft und zwar weil es auf einem so genannten Vektorraummodell basiert, in dem eine Wortbedeutung durch einen Vektor repräsentiert ist. Semantische Ähnlichkeit wird über den Kosinus zweier Vektoren berechnet. Die entscheidende Idee dahinter, beruht auf der Distributionellen Hypothese (Harris, 1954). Als Endziel soll das System in Bilingwis eingebaut werden. Das System wurde manuell evaluiert.